Model Mania: What Are Weather Models?
Hello everyone!
This post is the first in a short series designed to give a brief overview of what weather models are and why they’re important. I hope that by understanding the basic ideas behind weather models, you’ll be better positioned to interpret the vast amounts of weather model data you encounter in your daily life, from our sites weather.us and weathermodels.com to the app you probably have on your phone, to local and national TV broadcasts. If you’re looking for information on the special flavor of weather models known as ensemble systems, I will explain those in a future series, which will be linked here when completed.
So what is a weather model?
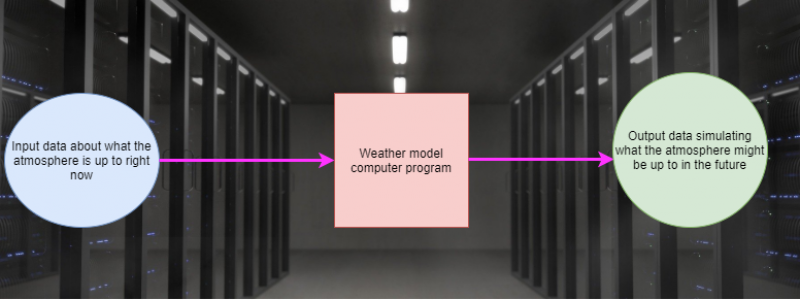
Simply put, a weather model is a computer-generated simulation of the atmosphere. At this point in our discussion of weather models, it’s probably easiest to think of them as a “black box” that does some calculations on a set of input data and produces some output data, somewhat analogous to how your middle school math teacher taught you to think of a mathematical function.

Of course, this depiction of a weather model is incredibly simplified, but understanding these three basic components is a critical first step in thinking more deeply about models and how they work. I should also note that this is a basic template for thinking about any type of modelling, not just that of the atmosphere. Models are used all the time to forecast economic parameters, behavioral trends in a population, traffic flow, and so much more. No matter what you’re trying to model, you need to know what’s happening in that system now (we’ll call these the initial conditions) and how the system works (usually described by a set of mathematical relationships known as governing equations) to arrive at your simulated output (the forecast).
It’s important to understand this process because to get an accurate forecast, you need an accurate set of initial conditions and an accurate set of governing equations. Forecast inaccuracies, in meteorology or elsewhere, will always arise from inaccuracies in one of the previous two modelling steps (initial conditions or governing equations).
With that in mind, how do we set up our initial conditions for a weather model? The only way to get perfect initial conditions would be to know the structure, speed, and direction of every molecule in the earth’s atmosphere. Unfortunately, that is and will always be impossible. Instead, we take as many observations of the atmosphere as we can, in hopes of figuring out the behavior of as many molecules as possible.
Here’s a look at a portion of the observations that go into one run of the weather model suite run by NOAA, courtesy of NASA’s Goddard Space Flight Center’s Global Modeling and Assimilation Office. Each dot represents one observation, with the dot’s color corresponding to that observation’s source. A similar set of observations is produced every hour of every day, though the frequency of measurements by different observation sources varies. For example, satellites can take measurements as frequently as every 30 seconds while conventional surface observations are generally taken every hour, and conventional upper air observations occur only twice each day.
There are two key takeaways from this map: a mind boggling amount of data is continuously flowing into our weather models, but tremendous gaps still remain. For example notice the nearly complete lack of observations over places like the Sahara Desert and Siberia. It might seem relatively unimportant to know what the atmosphere is doing over these sparsely populated areas, but their weather has a surprisingly direct influence on the conditions we experience here in the US. For example, the upper level disturbances that produce our wintertime nor’easters frequently originate in the brutally cold airmasses of Siberia. In the summertime, it’s the intense heat of the Sahara that helps produce tropical waves which can turn into powerful hurricanes as they move across the Atlantic. To forecast high-impact weather events here in the US, we need to know what’s happening from the Sahara to Siberia and everywhere in between, but we don’t. That means that the best we can do is make an educated guess about what’s happening in parts of the atmosphere we can’t measure, and send that guess off to the governing equations part of the model. Gaps in our observations and the inherent errors that come with the approximations we use to fill in these gaps remains a very important source of forecast uncertainty no matter where you are in the world, even if we have lots of observational data in your local area.
Similar issues arise from the series of governing equations used to describe atmospheric processes. Describing these errors in any detail would require a fairly deep dive into advanced mathematics and physics, which is beyond the scope of this article. Suffice it to say that even in a hypothetical world where we knew what every molecule in the entire atmosphere was doing at a given time (i.e. perfect initial conditions), we still have an imperfect understanding of all the interactions that might happen between the molecules over a given amount of time. Additionally, there are some cases where we know how molecules interact with each other conceptually, but lack a computationally feasible way of expressing those interactions mathematically. In these cases, the best we can do is come up with a reasonably good approximation and move on with our calculations.
The errors introduced by the approximations used in the data assimilation and governing equation steps of the weather model have shrunk dramatically in the past decades, and forecast accuracy has increased as a result. However, even the relatively small errors we’re dealing with now have enormous impacts on forecast accuracy because their magnitude compounds exponentially over time. If the model error for the initial position of a storm system now is one mile, it might be 100 miles off by day five and 500 miles off by day 10.
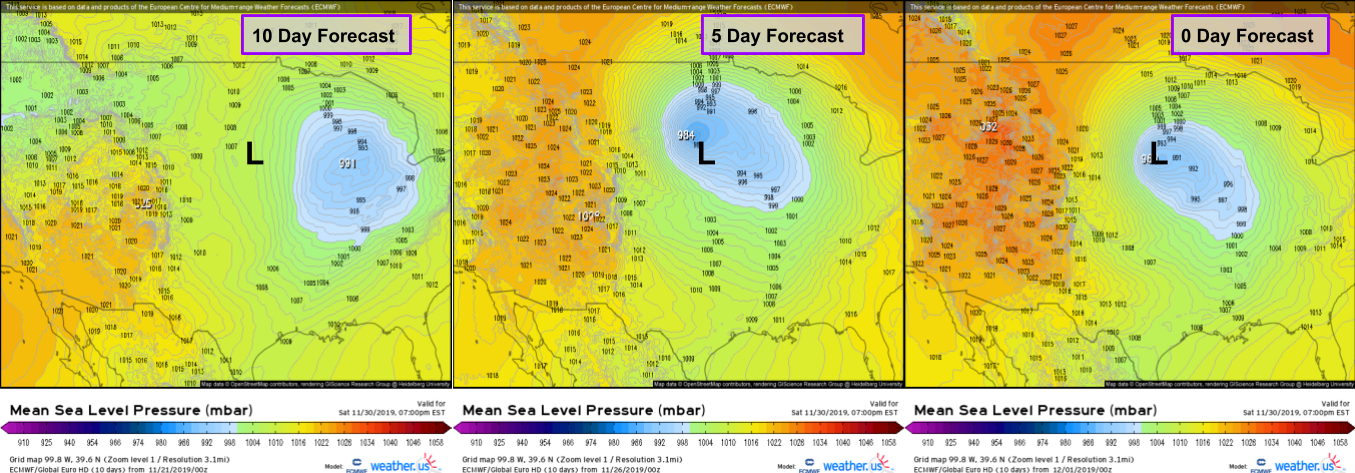
This graphic depicts the 10, 5, and 0 day forecasts for a storm over the Central Plains by the ECMWF model, statistically demonstrated to be the best available weather model. Even the best model’s 10 day forecast for the storm was wrong by almost exactly 500 miles. The 5 day forecast performed much better, with an error of around 150 miles. I’m sure the 0 day forecast (the model’s initial conditions at the time of the storm) wasn’t perfect but its precise error is impossible to calculate due to observational gaps.
Hopefully by this point you have a better understanding of the three basic elements of a weather model- initial conditions, the calculation of governing equations, and the resulting forecast. I also hope you’ve gained a better appreciation for the sources of error in weather models, both at the observational (initial conditions) and calculation (governing equations) stages of the process.
In the next post of this series, I’ll discuss the differences between two major ‘flavors’ of weather models, those dedicated to predicting global weather patterns, and those dedicated to predicting regional phenomena.
-Jack
About the author

Jack Sillin
Jack Sillin is an Atmospheric Science student (Cornell '22) and weather forecaster who regularly writes for weather.us and upportland.com. Follow me on twitter @JackSillin.



Would Love to Find the other Model Mania Posts. There are Terrific Articles to be Re-Read again and again. Hope you can Help. May I wish you a Very Happy and Healthy New Year. I am a Criminal and Matrimonial Trial Lawyer and former Nassau County Assistant D.A. I love Meteorology and received the Distinguished Service Award from both the National Hurricane Center and New York Weather Forcast Office in 2017. I have also Lectured at National Hurricane Center Conference.Weather Models etc is the Go to Site. Learning a lot which I will use in Educating the Public in the Town of Oyster Bay where I held Public Office as a Councilman
Hi Leonard, thanks so much for the kind words about the Model Mania series! Each post has links to the others, but if for some reason those don’t work, just search “Model Mania” in the box on the left of the page and you should see all five pop up. Hope this helps!
Jack